
EB JEPAs in jepax
Published:
Recently a paper proposing Energy-Based Joint-Embedding Predictive Architectures EB-JEPA came out and had some interesting perspectives JEPAs that I will discuss and I wanted to include in jepax. We have previously covered the first JAX implementation of a JEPA, I-JEPA in a previous post.
First, the question arises, what makes these JEPAs “energy based”? They say “An EBM defines a scalar energy function E(x,y) measuring compatibility between inputs x and outputs y, where low energy indicates high compatibility. Learning consists of shaping the energy landscape so that correct input-output pairs have lower energy than incorrect ones.” and thus you can achieve training by minimizing E, subject to some regularization to prevent universally minimizing E. This seems like a more general concept than energy based models, in which your scalar energy function actually represents the un-normalized distribution (perhaps why they call them energy based JEPAs and not energy based models). It isn’t clear whether this energy objective carries any practical impact that would normally be associated with energy based models (since EBMs have certain properties, e.g. sampling, composability, etc.). Perhaps on a smaller problem it could be actually measurable, but does the energy learned by these JEPA regularized approaches actually look like the energy landscape? Does it match the true energy better or worse than other, more explicit, EBM methods (e.g. contrastive divergence)? Can we sample from these models? These are just some of the interesting questions that the energy based framing of SSL brings up, although I don’t seem them frequently addressed.
But perhaps the more interesting question is, what makes these EB-JEPAs JEPAs? If you look at Figure 2 of the I-JEPA paper, you will see that a JEPA is distinguished from a Joint-Embedding Architecture (JEA) through its predictive component (in the embedding space), and in the background, Section 2, the authors remark that JEAs can be cast in this energy minimization framework. Many more common forms of JEA exist, e.g. SimCLR, but come with tradeoffs as the paper outlines. In the EB-JEPA, they present an image JEPA that looks quite different (their image example looks like Fig 1 of SimCLR, along with the usage of image augmentations, unlike I-JEPA). It seems at first glance to be more of a JEA than a JEPA. However, these are not solid lines, and equations (1) and (5) reveal more insight into these differences. Although the image case has no $g_\phi$ (predictor), it would seem like a JEA, but really a JEA is a subclass of JEPAs (in which predictors are identity functions).
In jepax we are able to recreate similar performance to the published results, see the figure below.
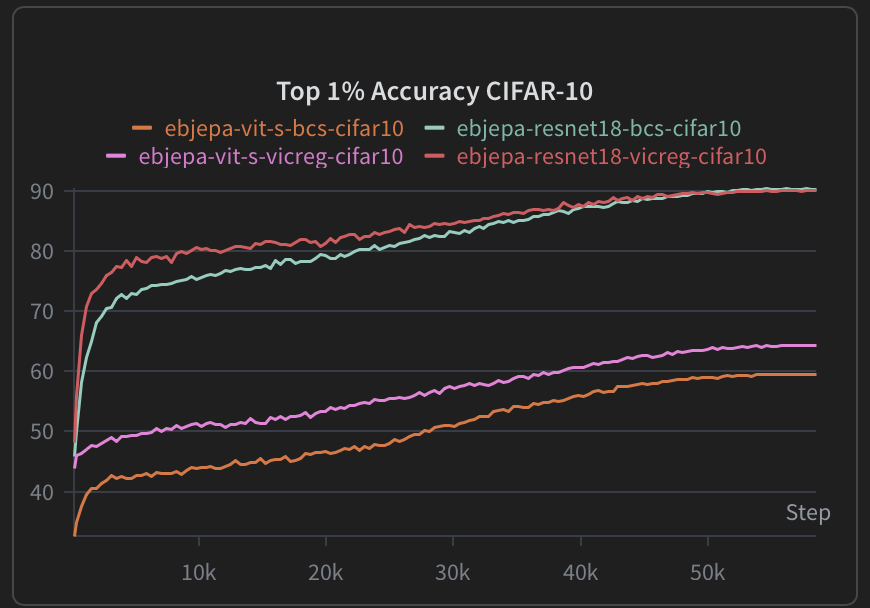
Interestingly, ViT based models seem to substantially underperform ResNet/CNN architectures. We investigated a variety of architecture choices (e.g. Batch Norm, Group Norm, depth, size, loss weightings, etc.) and found this performance to be generally representative. However, it is often said that ViT (and transformer based models more broadly) require more data to achieve high quality performance, so this may simply be an example of that phenomenon. Additionally, we saw similar results with I-JEPA, with the ViT performing much better on ImageNet1k than on CIFAR-100.
With the above in mind, we are hopeful that the addition of EB-JEPAs in jepax will allow for faster and more fruitful explorations of JEPAs and further support the growth of JAX based JEPA researchers.
Changelog
- February 25, 2026: Published initial version.